语言模型效果的评估一直是一个比较头疼的问题,如果差距很大其实我们是可以感知出来的,但是一些能力上差不多的模型就不太好进行排名,有时候数值上的优势并 不能代表整体感受。
所以这里介绍一下Chatbot Arena 排行榜这个项目。他们采用了 Elo 评分机制来评价语言模型,简单来说就是让用户使用同一条提示判断两个匿名语言模型的输出结果的好坏。然后将所有用户的评分汇总之后进行计算最终得分。
ELO 评分体系是一种为棋类和其他竞技性游戏设计的评级和排名系统。ELO 评分体系的基本原理是,每位选手都会被赋予一个初始评分,然后在与其他选手比赛后,根据比赛结果对评分进行调整。如果一个选手在比赛中获胜,他们的评分将上升,而失败的选手的评分将下降。评分的调整幅度取决于选手之间的评分差异,以及比赛结果是否符合预期。
所以这样的评分体系是最接近语言模型带给人的感受的,而且很很好的评价他们的综合能力。
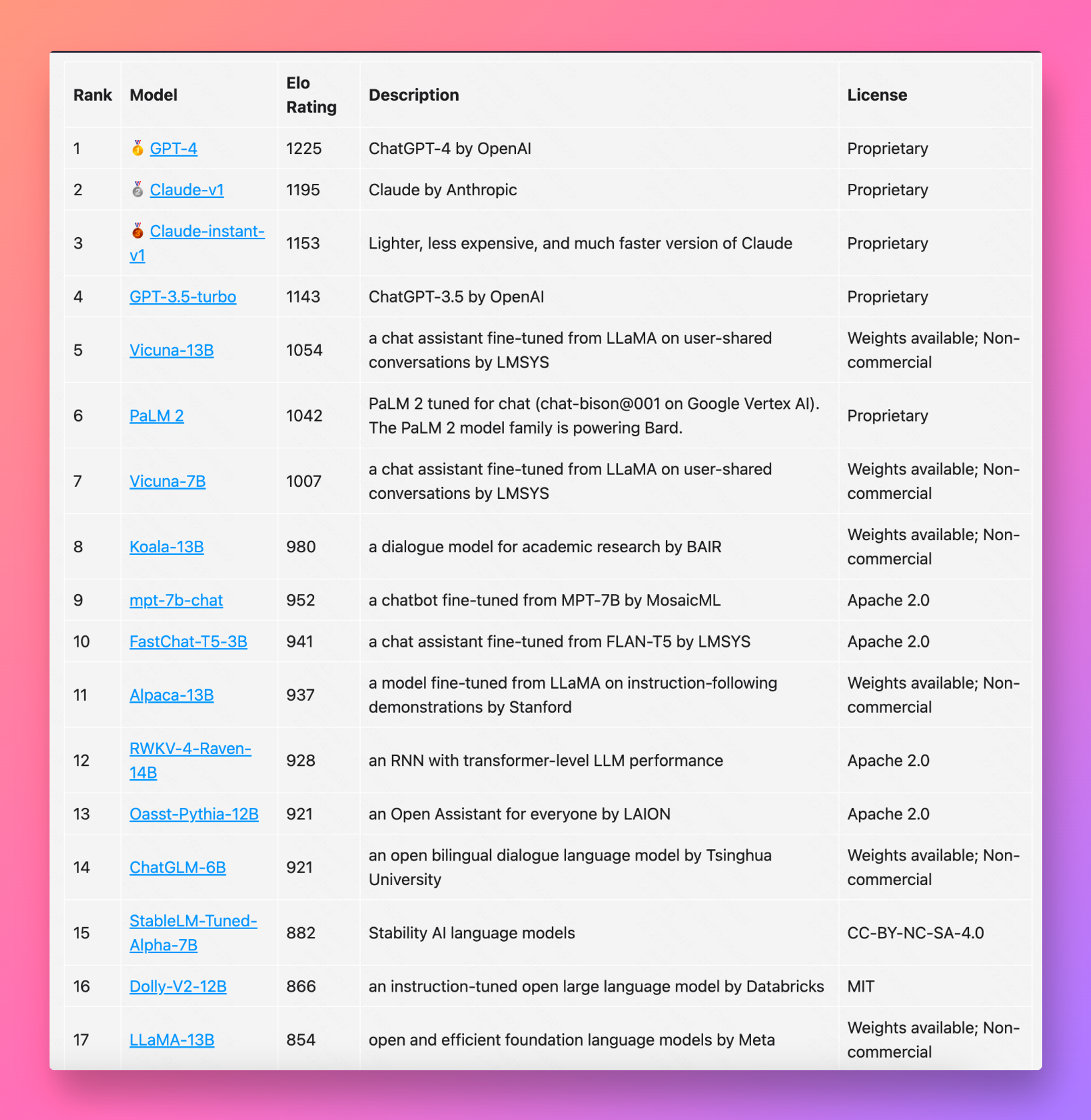
下面是截止目前的一些语言模型的评分排名,前四名的排序几乎没变,这周是谷歌的PaLM2 第一次加入评分,现在看来跟前面几名都有不小的差距,甚至都比不上 Vicuna-13B。他们通过对评分的分析觉得可能是下面几个原因造成的:
- PaLM 2 似乎比其他模型受到更严格的监管,这影响了它回答某些问题的能力。
- 当前提供的 PaLM 2 只有有限的多语言能力。
- 当前提供的 PaLM 2 的推理能力不是很令人满意。

那有的人可能发现了可能上面的中国模型不太多,在 Github 也有一个项目是专门对中文语言模型进行评价的,中文通用大模型基准(SuperCLUE)。
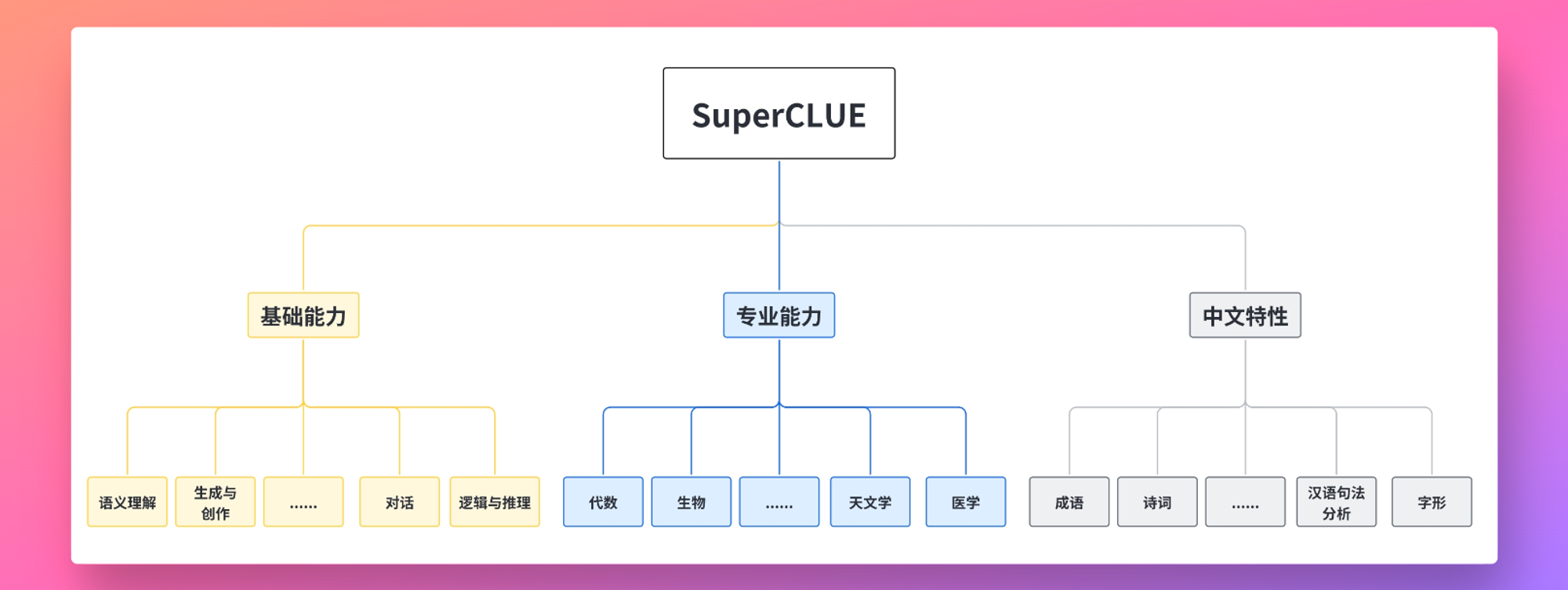
上面这张图可以比较清晰的解释他们的整个评价体系,SuperCLUE从三个不同的维度评价模型的能力:基础能力、专业能力和中文特性能力。具体的细节可以到他们的项目页面查看:
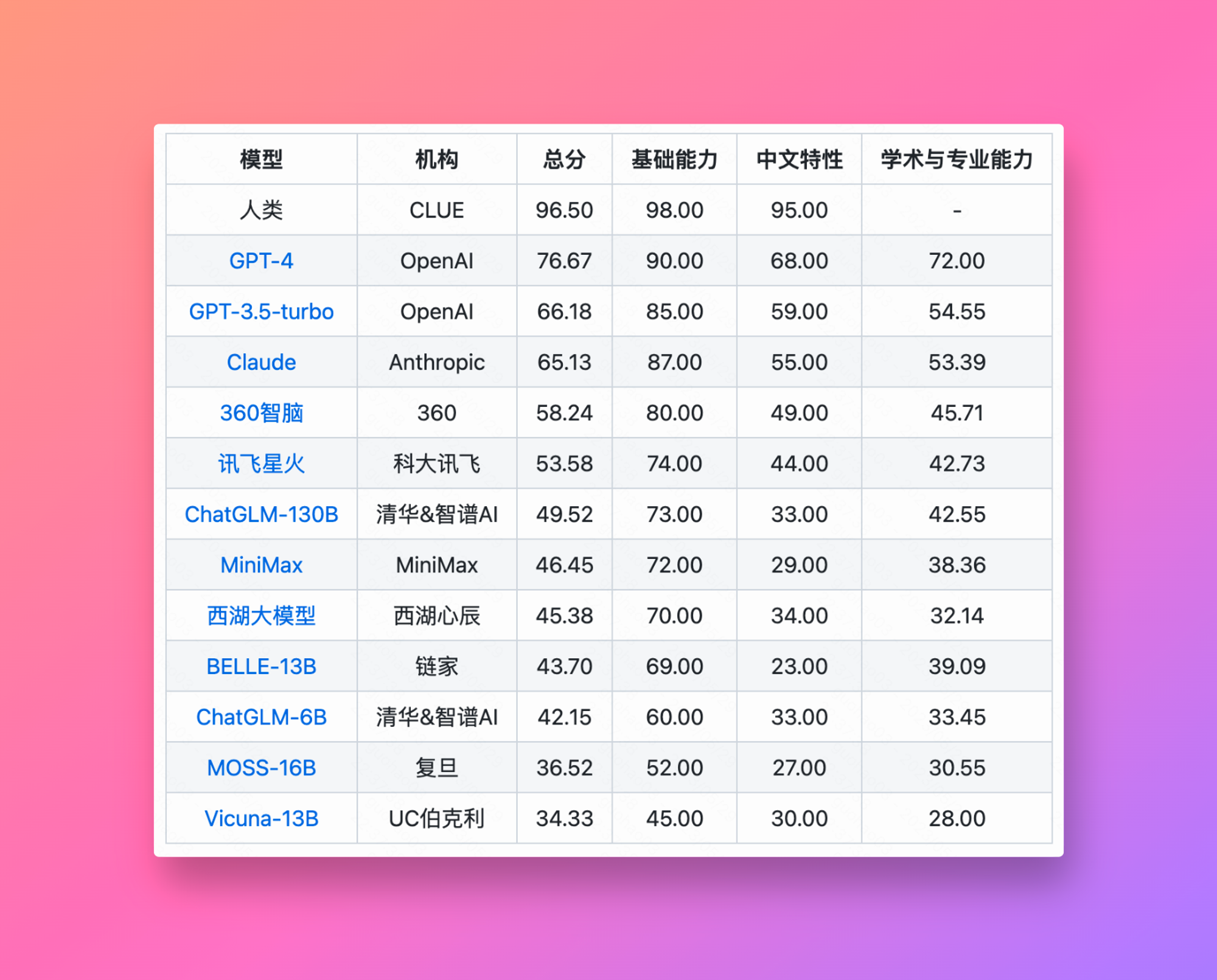
https://github.com/CLUEbenchmark/SuperCLUE 下面是目前他们 1.0 的中文语言模型排行:
原创文章,作者:校长,如若转载,请注明出处:https://www.yundongfang.com/Yun231094.html
 微信扫一扫不于多少!
微信扫一扫不于多少!  支付宝扫一扫礼轻情意重
支付宝扫一扫礼轻情意重 